

If you’ve ever been given a PDF that cannot be searched through by way of Ctrl + F or one that produces a random string of weird symbols – like above – when you copy paste from it, you may have the problem of custom encoded fonts.
Custom encoded fonts are non-standard fonts that your computer cannot parse and thus makes the text inside of a PDF rather useless outside of simply reading it and maybe making physical prints.
There are some ways to fix custom fonts, such as contacting the creator of the PDF and asking if they have that font available for you, but today we’re looking at another option.
Using Adobe Acrobat we will turn the entire PDF into an image and then use the software’s built-in optical character recognition (OCR) to turn those images into usable text.
We know that some free PDF readers and online tools claim to be able to do these same processes, but we’ve only had success with Acrobat so far.
On top of this we do have to thank Adobe customer service rep “Frebin” who helped us solve this problem a few years ago. When it popped up again in 2020 we knew that an online resource like this could help others.
Step 1: Check if custom encoded fonts are really the problem
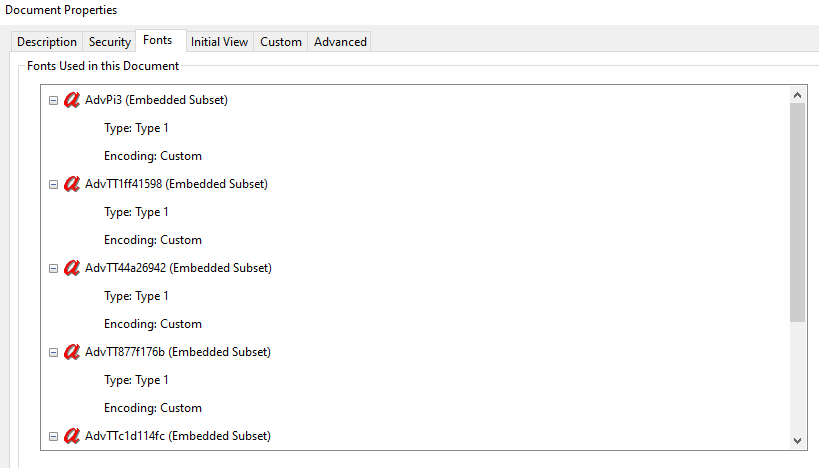
Hit Ctrl + D on your keyboard to bring up the document properties and then go to the Fonts section.
If you see that the encoding type of the fonts is “Custom”, like in the screenshot above, then proceed to the next steps.
Step 2: Convert the PDF into images
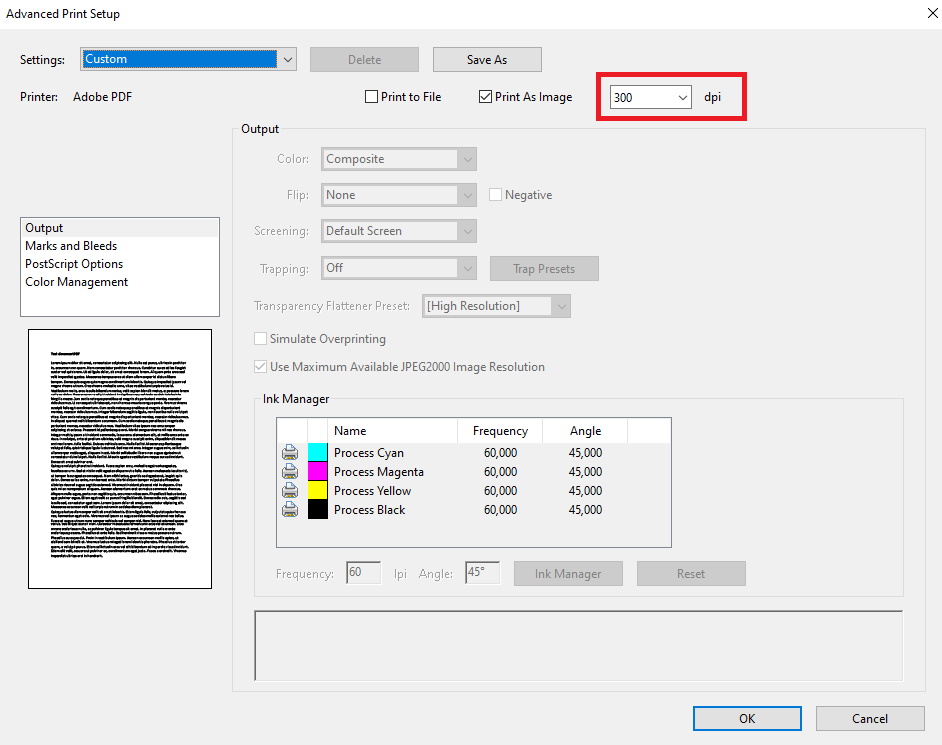
Press Ctrl + P to bring up the printing menu in Acrobat. Change the printer to “Adobe PDF”.
Click on the “Advanced” button to be taken to that set of options. Once there, click on the “Print As Image” option. The standard 300 dpi default setting should be fine.
Click on OK and then print. You will then be prompted to save the new PDF file somewhere on your device. Do so and then open the new file in Acrobat.
Step 3: Use the optical character recognition

On the right side of Acrobat there is a green icon that looks like a printer. Click it to open the “Scan & OCR” options which will then open at the top of the screen.
Choose the language that the document was originally written in and click on “Recognize Text”.
This process may take a long time depending on how long the document is and how much text is in it. Acrobat may also crash at this point if the document is exceptionally large. If this happens repeatedly you may need to split the PDF into multiple parts. Here’s how to do that.
When the process is over hit Ctrl + F to search through the document to test if everything worked. If you can easily search through and copy / pasting text works as intended, then everything was successful.
Problems and alternate fixes
Even if the above works as intended you may find some problems arise. The most common for us were caused by the OCR not being able to differentiate between certain things because of the quality of the original document.
Common problems we found were the letters r and i next to each other being interpreted as an “n” instead, full stops being completely removed, and random capitalisation and bolding of certain words or letters.
These can usually be fixed by using find and replace.
We’ve also heard of some people being able to fix this problem using Distiller – a sub-programme included with Acrobat. Instructions to use it are here but we’ve never found success with it. If nothing else has worked for you it may be worth a shot.
Finally, remember to keep backups of everything you do, especially the original document. If you make a change that can’t be reversed or an irreparable error, you’ll be happy to have a copy of the original on hand.

